PowerBI Incremental Refresh in the Age of Data Lake Houses

Data lake houses are becoming more popular. This means that as business analysts we need to get more comfortable with this data lake architecture and how to utilize it for our reporting needs.
What is a data lake house?
A data lake house is basically a compute engine that sits on top of data lake files (in Synapse we call this a Serverless SQL Pool, but you may be familiar with Delta format and Databricks as well). Rather than persisting the data in a database as analysts are often used to, this architecture instead persists data in raw files (often parquet or delta files). This is a very cost-efficient way of storing and querying data; storage costs are generally lower than in traditional data warehouses and we only pay for the compute when we use it (you gotta love the cloud!).
Why should a business analyst care about this?
The efficiency in accessing the data contained in the raw files is based on the partitioning structure and type of file. If you’re not familiar with partitioning structures in data lakes, think of a folder structure from a storage perspective, but an index from retrieval perspective. There is lots of great literature available on structuring data lakes as well as the differences between formats like parquet and delta, so we won’t be getting into details here. Instead, in this article we’re going to tackle how to implement incremental refresh in PowerBI using a commonly found partitioning structure; yyyy/mm/dd. We’ll be using Azure Synapse Serverless Pools with a Parquet file format.
Setting up the data lake house
For the rest of this article I’m going to assume you have your data in parquet format partitioned by year, month, and day. In Synapse, the most common way to expose this data for reporting is a SQL Serverless Pool view. In fact, in a logical data warehouse structure, we’ll have dimensions and facts exposed as views so our analysts can interact with our data using t-SQL (as if this parquet data was a SQL Server table).
In Synapse, to facilitate partition elimination (ie. only read the files from the relevant year, month and day folders) we need ensure our Serverless view is created using the filepath() function to expose the partition fields as columns. Here’s an example create view statement:
CREATE VIEW [incrdemo].salesorder
AS
SELECT
CAST([result].filepath(1) as int) as [Year]
,CAST([result].filepath(2) as int) as [Month]
,CAST([result].filepath(3) as int) as [Day]
, *
FROM
OPENROWSET(
BULK 'https://MYSUPERSECRETSTORAGEACCOUNT.dfs.core.windows.net/datalakehouse/ParquetFiles/Fact_SalesOrder/yyyy=*/mm=*/dd=*/*.snappy.parquet'
, FORMAT = 'PARQUET'
) AS [result]
Note that we cast the
filepath()results to int type (this is to facilitate a greater than/less than comparison in our queries).
With this view created we can now query our parquet files as if they were a SQL Server table/view like this.
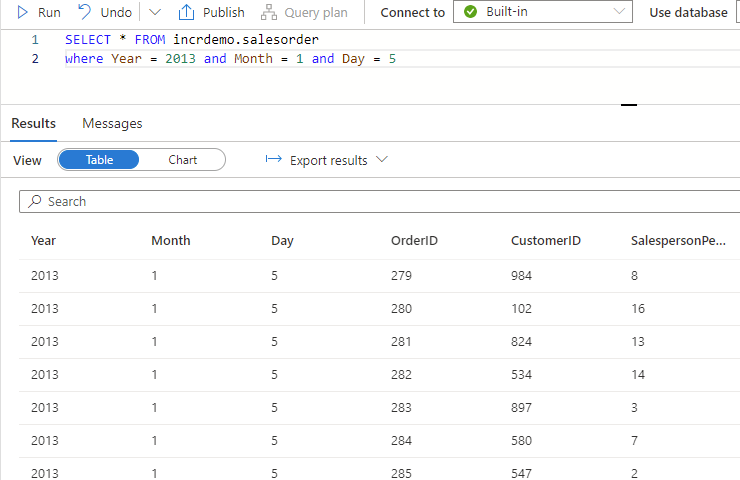
Note that since we used filepath to create our Year/Month/Day columns, the Synapse Serverless Pool will only read data from the file(s) in the folder path specified in our where clause (ie. Partition Elimination). When dealing with “big data” this can significantly increase performance for queries that utilize predicates based on our partition structure.
In the example above, Synapse will read files in this partition folder; /Fact_SalesOrder/yyyy=2013/mm=1/dd=5.
Awesome! This is the first step to ensuring an efficient refresh operation. But now we have a new problem; PowerBI only allows us to use datetime fields for incremental refresh.
Incremental Refresh in PowerBI
Note: If you’re not familiar with Incremental Refresh in PowerBI review this doc
One solution is to update our view to create a datetime field from our filepath parameters;
cast([result].filepath(1) + '-' + [result].filepath(2) +'-' + [result].filepath(3) as datetime) as incrementalRefreshDate
But what if we don’t have the option to update our backend view?
Good news! We can do this in PowerBI.
After we create our RangeStart and RangeEnd parameters we need to map them to 3 fields; Year, Month and Day.
Here’s where things get fun.
The general use case for incremental refresh is simple; we have a datetime field in our table and we simply filter it for >=RangeStart AND <RangeEnd
However, in this case we don’t have a datetime field.
The first thing we may consider would be to break up our RangeStart and RangeEnd into its components and compare them individually. But this wont work since our range will often cross months or years. Consider the range; Jan 30, 2013 to Feb 2, 2013 for instance. We can easily see that our Day clause would fail as there is no day number that could meet the clause >30 AND <2.
Instead, we can combine our 3 columns for a single comparison against our RangeStart and RangeEnd. One really eloquent way to do this which my colleague Alex Powers crafted is to convert our RangeStart and RangeEnd to integer values, and then construct a similar integer value from our Year, Month and Day columns. Here’s a function that you can use to convert the RangeStart and RangeEnd to integer representations;
fxConvertIncremental
(#"Date value" as datetime) as number =>
Number.From(
DateTime.ToText(
#"Date value",
"yyyyMMdd"
)
)
The DateTime.ToText function will create a text representation of your datetime, for example “20130501”.
The Number.From function will then convert this text value to an integer 20130501 (or 20,130,501).
We then simply convert our Year, Month and Day to a similarly formatted integer, which can be done as follows:
[Year]*10000 + [Month]*100 + [Day]
Thus 2013, 5, 1 becomes 20130501 and can be compared to our RangeStart and RangeEnd parameters.
And our M query can be updated to filter our table as follows:
#"Filtered Rows" =
Table.SelecRows(
incrdemo_salesorder,
each
([Year]*10000 + [Month]*100 + [Day]) >= fxConvertIncremental(RangeStart)
AND
([Year]*10000 + [Month]*100 + [Day]) < fxConvertIncremental(RangeEnd)
),
Confirming our query is folding
Query folding is the key to making incremental refresh work. When a query “folds”, it means PowerBI is pushing logic to the source system to do work for it. In this case, filter the data by date before returning results to our client. We can confirm query folding is occurring by viewing the native query in PowerBI. To do this, right click the last step in your M query and select “View Native Query” as below.
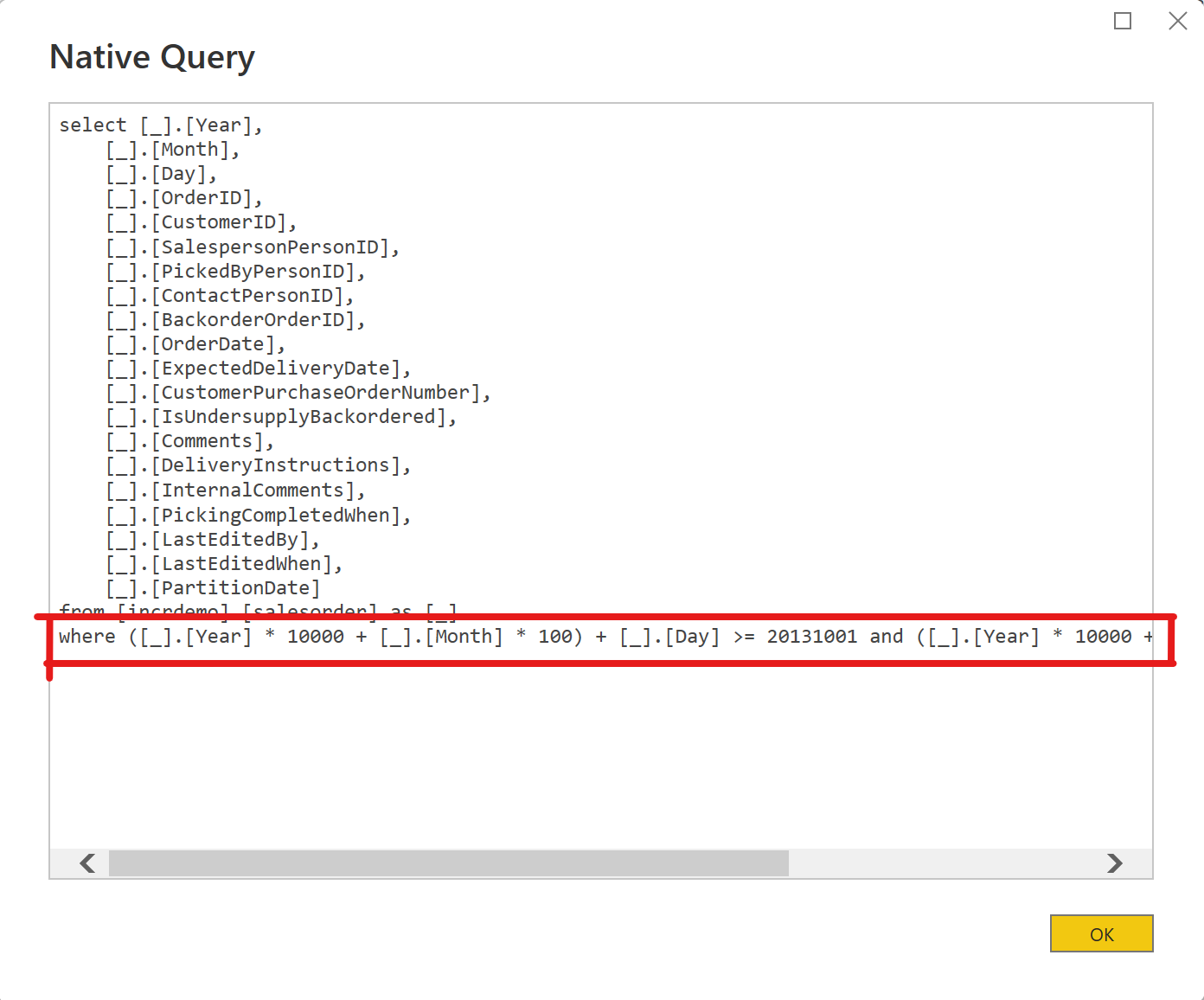
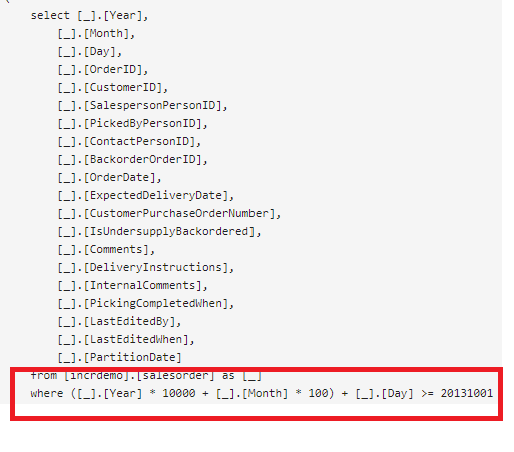
Alternatively, we can check the logs at our source to view the query it receives from PowerBI. In my Synapse instance I can see PowerBI issue a query with the appropriate “where” clause.
Great! So now we have a PowerBI query that folds to Synapse Serverless SQL and we can incrementally load our fact data.
But can we confirm that Synapse is only reading the relevant parquet files (i.e. performing partition elimination)?
You betcha!
Confirming Synapse is still using partition elimination
To confirm this, we’ll head over to SQL Management Studio and query our view twice:
- First with no filters applied (i.e. Select * from vw),
- Second with our incremental filter on it.
We’ll then compare the data scanned.
Here’s what my system returned:

With no filters applied we can see that 21MB of data was scanned, and twice that amount was moved.

With our filters applied we scan and move only 1MB of data.
An alternate method of confirmation using storage logs
Alternately we could check our storage account logs to see the reads that Synapse issues to our storage account files when we query with our filters applied.
- First thing we need to do is ensure we’re capturing logs for our storage account (link)
- Next, we need to refresh our data in PowerBI to kick off a request to Synapse
- Finally, we view our logs and note the storage reads (note it can take a few minutes for them to appear)
If you push your logs to Log Analytics, you can use a KQL like this one below to query.
StorageBlobLogs
| project TimeGenerated, OperationName, Uri
| where TimeGenerated > ago (10m)
| sort by TimeGenerated
Here’s my result:

Voila! We can see that Synapse is reading the correct folder based on the parameters of the incremental refresh.
Conclusion
Designed correctly, we can efficiently refresh our PowerBI models based on a Data Lake House architecture using a combination of SQL Serverless pools and Incremental Refresh!